Data Integration, Visualization and Analytics VOR 7235
ReturnData Integration
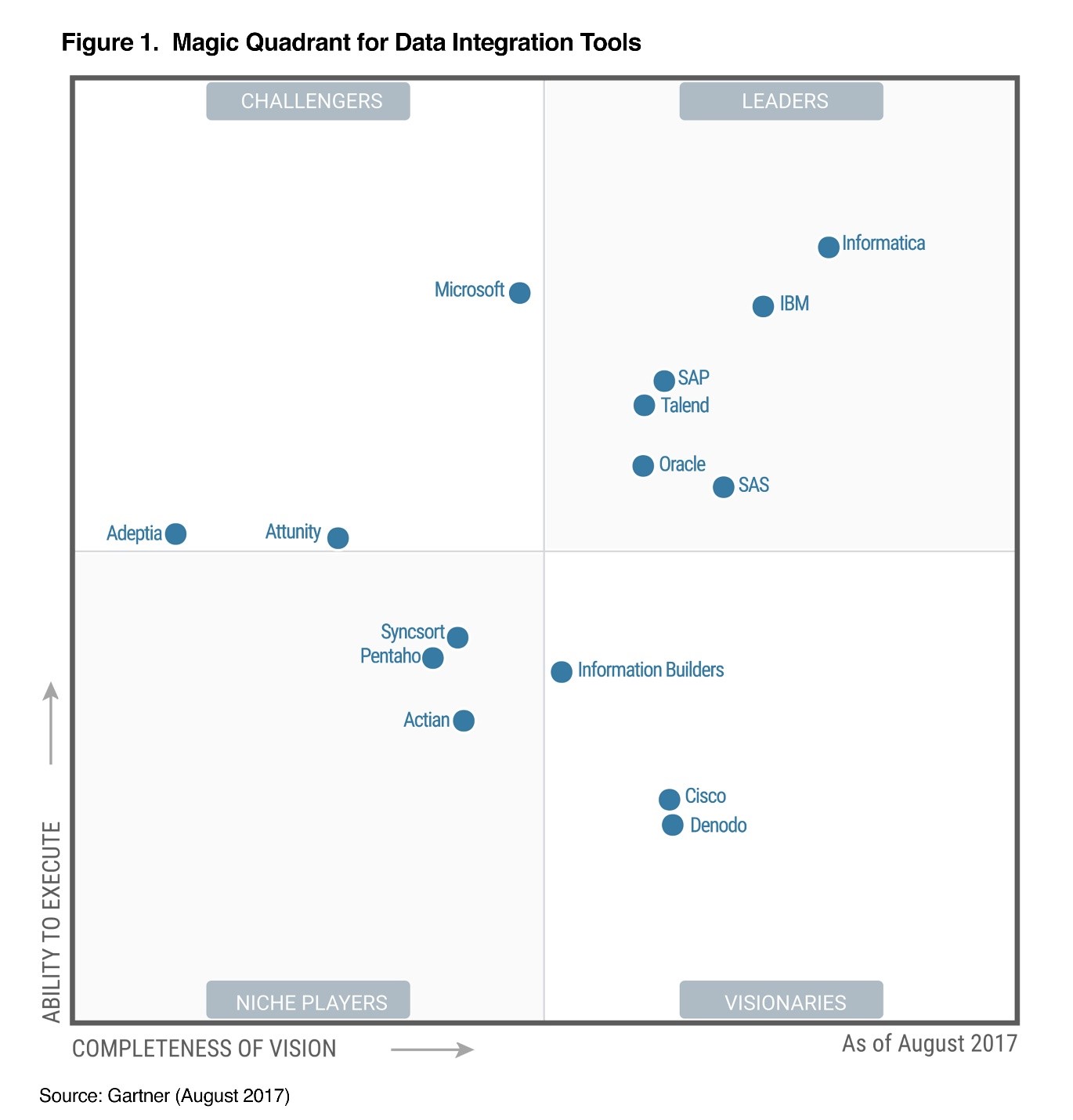
Data Integration (DI) and Data Quality (DQ) play a major role in overall Data Architecture and are crucial to make data management successful.
CM Inc.'s DI/DQ services enable our clients to gain a competitive advantage in today’s global information technology by empowering them to access, integrate, and trust their information assets; They enable IT executives, architects, and managers to provide trusted, relevant data to the business – when and where it is needed.
We provide Data Integration Services that support multiple sources and targets with transformations developed and deployed through a GUI. We discover, cleanse, monitor, transform and deliver quality data to our clients.
We access data from many different sources, integrate those data and deliver the integrated data to our clients so that clients can gain one view of all their data and can stop wasting time looking for it in silos.
CM Inc. has all the resources your organization needs, including the tools and accelerators, the industry’s leading data integration-specific methodology, and the experienced team, to successfully guide your data integration projects from strategy to completion.
DIVA Data Integration Basic Features
- a) Basic requirements to ensure functionality and ease-of-use for users
- b) Platform and Architecture: a conceptual blueprint describing the structure, behaviour and views of a system, incorporating long-term flexibility
- c) Extract, Transform and Load (ETL)
- d) Data Cleansing: the process of detecting and correcting (or removing) corrupt or inaccurate records from a data set, table, or database
- e) Administration and Workflow: processes which include human or system-based steps
- f) Audit Versioning and Recovery: provides a chronological record of system activities to enable the reconstruction and recovery from an event.
- g) Big Data Processing
Product(s) proposed under this Capability, must be able to deliver on:
- 1) Support packaging of selectable changes into a package that can be deployed to any environment without any changes to the package.
- 2) Support reporting exceptions in any of the functional categories such as extraction, transformation and loading (ETL).
- 3) Provide a high-level of performance through scalability, acceptable response time and throughput and are able to provide performance statistics.
- 4) Provide audit statistics with respect to ETL.
- 5) Allow for triggering based on time, e.g., software can be scheduled to run at a particular time, events, or the status or outcome of other jobs.
- 6) Monitor batch jobs through a multiple means, e.g., via GUI interface, email, web-based reporting.
- 7) Ability of the server component of the Product(s) to run on multi-platforms such as the Windows server operating systems and UNIX, e.g., Sun Solaris.
- 8) Support industry standard formats, protocol and bindings, like Simple Object Access Protocol (SOAP), JavaScript Object Notation (JSON), Web Services, XML, WSDL, WS-Security, Java Message Service (JMS), and Enterprise JavaBeans (EJB).
- 9) Support multiple versions and/or instances for development, testing, User Acceptance Testing (UAT) and production environments, each with different security access.
- 10) Support parallel execution and scheduling parallel jobs and/or tasks.
- 11) Generate native SQL code behind the scene for ETL processes and provide user capability to override the structured query language (SQL).
- 12) Support multiple languages for custom development, e.g., Javascript, Java, and Python.
- 13) Access, extract, and load with configurable levels of security from multiple source and/or target formats and platforms, including relational databases; hierarchical or mainframe databases, e.g., IMS databases; flattened databases; flat files (CSV, fixed length); sequential access method databases (ISAM, VSAM); XML files; spreadsheets; unstructured data sources (PDFs, DOCs, images); No-SQL; JSON; Windows; Unix.
- 14) Capture changes automatically in data sources as they happen for processing and routing to multiple target applications.
- 15) Join heterogeneous data from multiple sources into a single mapping.
- 16) Provide a way to trace data lineage from source to target.
- 17) Support pull capability that enables the application to pull data from source databases and source systems.
- 18) Provide non-intrusive real-time or near-real-time trickle feed using source databases continuous data streaming technologies.
- 19) Provide “replace”, “append”, and “rebuild” data load options, as well as advanced options for data masking and de-identification.
- 20) Calculate, derive, parse numbers and strings to construct or break down data items and support complex transformation logic.
- 21) Write to multiple targets on multiple platforms from the same transformation logic in a single job.
- 22) Handle complex data integration rules, including spatial integration and spatial to spatial, and optimize the available resources in processing them.
- 23) Support loading and transforming of large object (LOB) data types.
- 24) support modular design and reusable objects for mappings, transformation rules and schedules
- 25) Support pre-built transformation functions and extensions thereof using a graphical IDE?
- 26) Support adding custom-built transformation functions to an extensible library for re-use.
- 27) Log changes made to the target databased for operational and audit purposes, with only changes made by the tool to be logged.
- 28) Support log-based change data capture (CDC) technology.
- 29) Support and manage surrogate key functionality
- 30) Support bulk loading to any target databased but not dependant on specific databases.
- 31) Integrate data cleansing module that can be incorporated into the ETL process in real-time as part of the source application.
- 32) Integrate data profiling capabilities and ability to natively profile any data source across the enterprise.
- 33) Support automated data profiling, i.e., table and column analysis.
- 34) Have dashboard and reporting capabilities to monitor and track data quality progression.
- 35) Create and/or import tables to check referential integrity, e.g., male, female, other or addresses.
- 36) Share and exploit metadata generated and/or created as a result of a data cleansing exercise with other tools and processes? Clients must be able to look at data patterns generated/created by the data cleansing component of the tool. This information should be available in CSV, SQL or other data files for further processing.
- 37) Provide centralized administration.
- 38) Recognize alert conditions such as run-time errors and communicate with an administrator through industry recognized protocols, such as email. The Product(s) must allow alert conditions to be defined and be role-based.
- 39) Ensure that extensive documentation is available free of charge with each acquired Product(s)’ license.
- 40) Provide usage statistics for various processes in the ETL workflow, e.g., for performance monitoring and change back, such as process durations with start and completion times; CPU load and RAM usage; Row counts; Historical analysis of previous loads and/or processes with detailed loads and/or processes logging and error information.
- 41) Have version control functionality.
- 42) Able to support recovery logic; recover to the point last completed successfully, after a crash without any manual intervention, restart ETL processing if a processing step fails to execute properly or restart the entire ETL session; provide an ability to configure actions for handling Problems with ETL process.
- 43) Have error tracking, handling and reporting capabilities.
- 44) Support scheduling ETL jobs by time, event, interval or condition and are able to restart ETL process from point of failure, check point or from the beginning as an error recovery process without any data loss and provide message notification feature in case of job failure.
- 45) Support content analysis, profiling, categorization of unstructured data including text mining and video and voice/audio analytics.
- 46) Support directly Hadoop file system (HDFS) query or access MapReduce.
- 47) Handle data lakes.